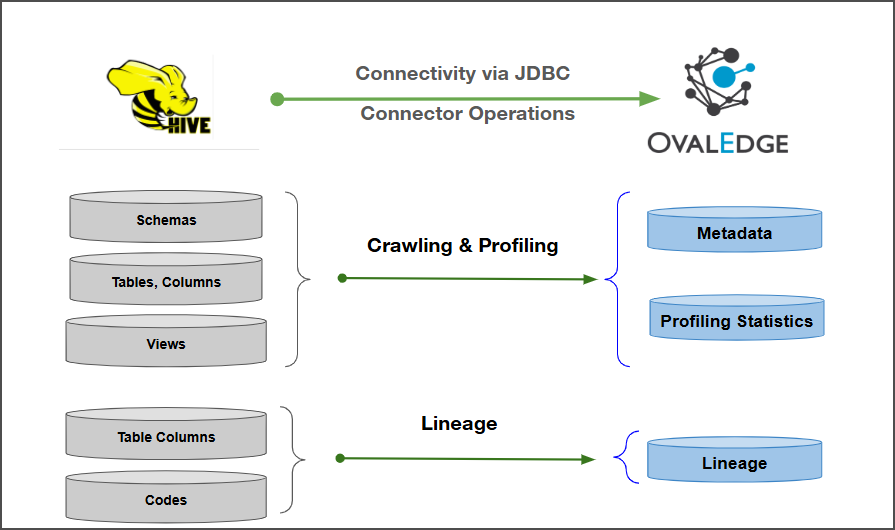
Connectivity
\[How the connection is established with Apache Hive]
| JDBC | | Verified Apache Hive Version | 5.8.0 | {% hint style="info" %} The Apache Hive connector has been validated with the mentioned "Verified Apache Hive Versions" and is expected to be compatible with other supported Apache Hive versions. If there are any issues with validation or metadata crawling, please submit a support ticket for investigation and feedback. {% endhint %} ### Connector Features | Feature | Availability | | -------------------------------------------- | :----------: | | Crawling | ✅ | | Delta Crawling | ❌ | | Profiling | ✅ | | Query Sheet | ✅ | | Data Preview | ✅ | | Auto Lineage | ✅ | | Manual Lineage | ✅ | | Secure Authentication via Credential Manager | ✅ | | Data Quality | ❌ | | DAM (Data Access Management) | ❌ | | Bridge | ✅ | ### Metadata Mapping The following objects are crawled from Apache Hive and mapped to the corresponding UI assets.| Apache Hive Object | Apache Hive Attribute | OvalEdge Attribute | OvaEdge Category | OvalEdge Type |
|---|---|---|---|---|
| Schema | Schema name | Schema | Databases | Schema |
| Table | Table Name | Table | Tables | Table |
| Table | Table Type | Type | Tables | Table |
| Table | Table Comments | Source Description | Descriptions | Source Description |
| Columns | Column Name | Column | Table Columns | Columns |
| Columns | Data Type | Column Type | Table Columns | Columns |
| Columns | Description | Source Description | Table Columns | Columns |
| Views | View Name | View | Tables | View |
| Objects | System Tables | Access Permission |
|---|---|---|
| Schema | USAGE on the database | USAGE |
| Tables | USAGE on the database SELECT privilege on tables | SELECT and USAGE |
| Table Columns | USAGE on the database SELECT on the table | SELECT and USAGE |
| Primary Keys (PK) and Foreign Keys (FK) | USAGE on the database SELECT on the table | SELECT and USAGE |
| Field Name | Description |
|---|---|
| Connector Type | By default, "Hive" is displayed as the selected connector type. |
| Authentication | The following two types of authentication are supported for Apache Hive:
|
| Field Name | Description |
|---|---|
| Credential Manager* | Select the desired credentials manager from the drop-down list. Relevant parameters will be displayed based on the selected option. Supported Credential Managers:
|
| License Add Ons |
|
| Connector Name* | Enter a unique name for the Apache Hive connection (Example: "ApacheHive"). |
| Connector Description | Enter a brief description of the connector. |
| Connector Environment | Select the environment (Example: PROD, STG) configured for the connector. |
| Server* | Enter the Apache Hive database server name or IP address (Example: hive-server.company.com or 192.168.1.10. |
| Port* | By default, the port number for the Apache Hive, "1000" is auto-populated. If required, the port number can be modified as per the custom port number that is configured for the Apache Hive. |
| Database* | Enter the database name to which the service account user has access within the Apache Hive. |
| Driver* | By default, the Apache Hive driver details are auto-populated. |
| Principal | Kerberos principal name for authentication |
| Connection String | Configure the connection string for the Apache Hive database:
Replace placeholders with actual database details. {sid} refers to Database Name. |
| Keytab | Kerberos keytab file for authentication. |
| Krb5-Configuration File* |
Path to the Kerberos configuration file (krb5.conf) required for authentication. |
| Field Name | Description |
|---|---|
| Credential Manager* | Select the desired credentials manager from the drop-down list. Relevant parameters will be displayed based on the selected option. Supported Credential Managers:
|
| License Add Ons |
|
| Connector Name* | Enter a unique name for the Apache Hive connection (Example: "ApacheHive"). |
| Connector Description | Enter a brief description of the connector. |
| Connector Environment | Select the environment (Example: PROD, STG) configured for the connector. |
| Server* | Enter the Apache Hive database server name or IP address (Example: hive-server.company.com or 192.168.1.10. |
| Port* | By default, the port number for the Apache Hive, "1000" is auto-populated. If required, the port number can be modified as per the custom port number that is configured for the Apache Hive. |
| Database* | Enter the database name to which the service account user has access within the Apache Hive. |
| Driver* | By default, the Apache Hive driver details are auto-populated. |
| Username* | Service account username used for accessing Hive. Note:
|
| Password* | Password for the service account user. Note:
|
| Connection String | Configure the connection string for the Apache Hive database:
Replace placeholders with actual database details. {sid} refers to Database Name. |
| Default Governance Roles | Description |
|---|---|
| Default Governance Roles* | Select the appropriate users or teams for each governance role from the drop-down list. All users configured in the security settings are available for selection. |
| Admin Roles | |
| Admin Roles* | Select one or more users from the dropdown list for Integration Admin and Security & Governance Admin. All users configured in the security settings are available for selection. |
| No of Archive Objects | |
| No Of Archive Objects* | This shows the number of recent metadata changes to a dataset at the source. By default, it is off. To enable it, toggle the Archive button and specify the number of objects to archive. Example: Setting it to 4 retrieves the last four changes, displayed in the 'Version' column of the 'Metadata Changes' module. |
| Bridge | |
| Select Bridge* | If applicable, select the bridge from the drop-down list. The drop-down list displays all active bridges that have been configured. These bridges facilitate communication between data sources and the system without requiring changes to firewall rules. |
| S.No. | Error Message(s) | Error Description & Resolution |
|---|---|---|
| 1 |
| Error Description: The JDBC connection string is invalid because the port and URI are incorrectly defined. Error Resolution: Enter a valid JDBC URI in the format:
Check network/firewall settings to allow connectivity |